The Case: As a financial institution we want to avoid fraud. Fraud is a broad term, so in this case, we focus specifically on identity theft. Ie. We want to be able to quickly detect oddities signaling that someone's identity is being used illegally. For this case study, we have discovered a fraud vector where applicants use similar email addresses. We want to add this check to our existing system with minimal effort and we want to be able to let it utilize all data we have.
Fraud is interesting. Not only because we as societies lose billions of dollars a year, but also because fraud finds its way through the cracks. Both characterization and techniques of fraud change as fast as it is profitable and that is fast in a globally connected world. But this also sets the bar high for the system to detect and flag fraud. It should always be able to embrace new patterns while not decreasing in performance. In this case study, we look at network technologies and how we can horizontally expand on the techniques. We also see how we implement these techniques in a way that allow for horizontal performance scaling.
First the data. In this example, we look at lending applications. We do not augment with data from other data sources although this can be added in transparently later and augment the results. An example of the applications could be as follows:
CaseId, Email, Amount, Name, Birth Date, Application Timecase007, tanjatt@example.com, 5000, Tanja, 1992-05-05, 2021-03-07 12:12:34case008, astriddd@example.com, 150000, Astrid, 1985-02-09, 2021-03-08 12:12:34case009, gert1970@example.com, 50000, Gertrud,1970-01-01, 2021-03-09 12:44:54case010, gert1971@example.com, 50000, Gertrud,1971-01-01, 2021-03-10 12:54:53This yields a network where the nodes are either an Application that has a case ID, an amount, and the time of application. These case IDs are linked to Applicants. An Applicant has a name, a birth date,
Next, we add in the email address layer. Normally emails would simply be a data field on the entities, but to detect similar emails, we can pull them out and build a new dedicated network that can be juxtaposed with the old one.
The email network is constructed such that similar email addresses are connected. We say that email addresses are similar when their Levenshtein distance is at most 2. This means that two emails are considered similar when only 2 edits are needed to make them identical.
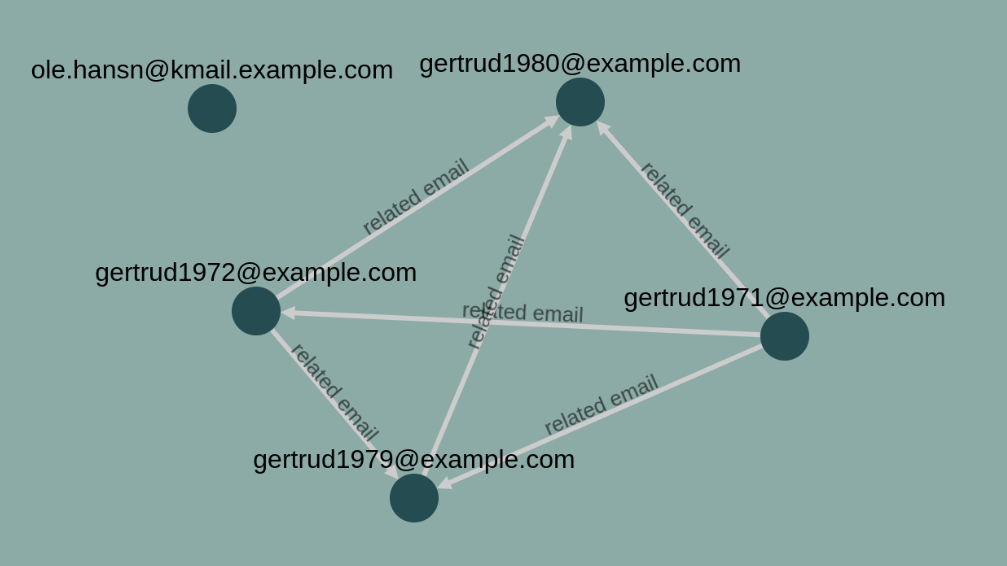
The email network and the lending applications network are connected such that applicants have a link to the email they possess. Now we can go from applicants to their respective email, go to a similar email and back to applicants again.
To efficiently use this product network we use a random walk technique. From a given entity, say case015 we take a random link out. We keep navigating around in the network randomly until we find a new entity of a specified type. In this case Application. By doing this thousand, or hundred of thousands of times we can draw a picture of how cases are interlinked. The blow picture is a result of that.
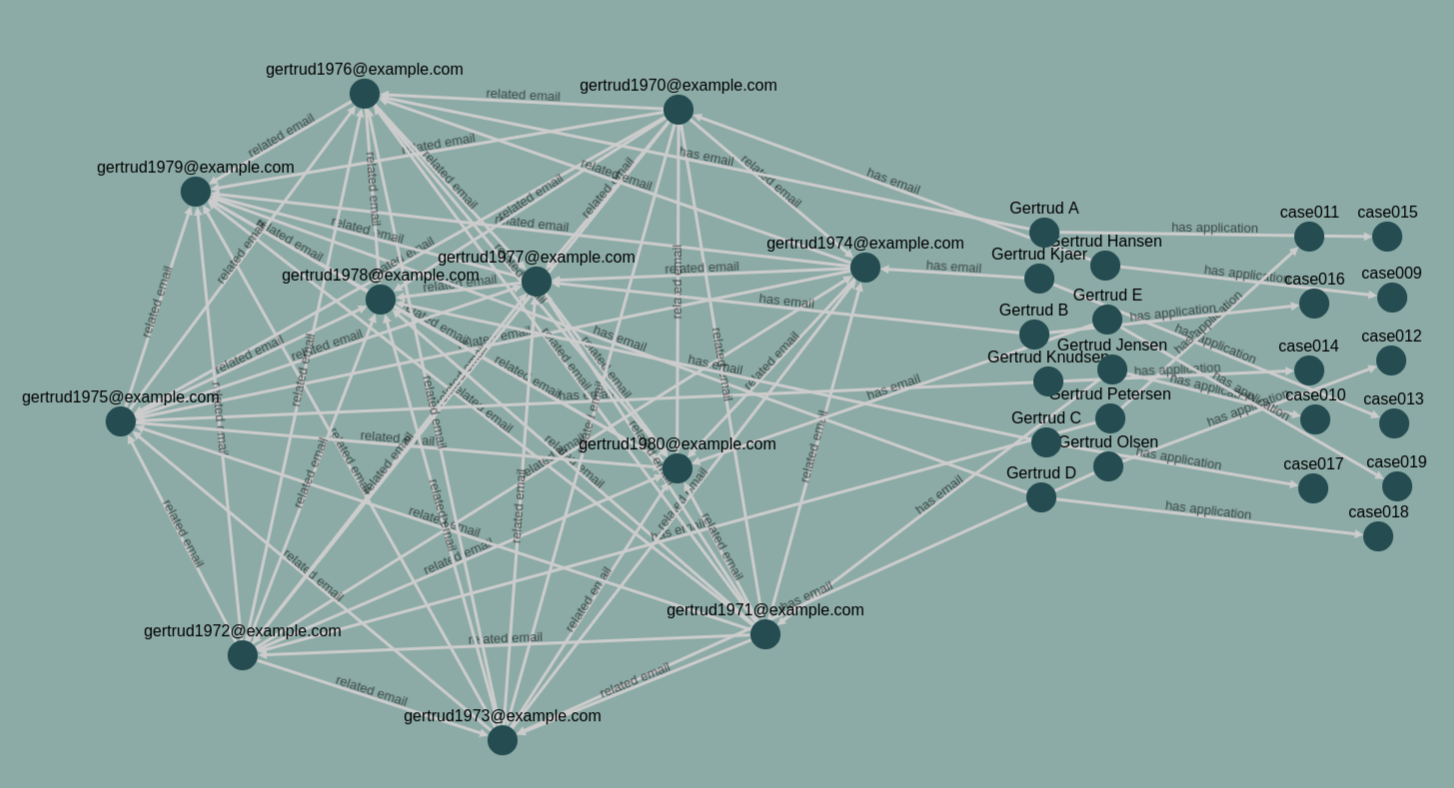
This picture is the result of 1000 random walks without excluding the walks that never ended in an Application. As we can see, it is quite efficient at finding a network of similar emails. This network will be flagged and an expert will take it on to assess an appropriate action.
Why This Solution?
There are several ways to achieve this. A more obvious way would be to issue
a SELECT query in SQL to get all applicants with similar emails. However, this
approach does not scale very well with new fraud vectors and constantly has to
be updated. The network approach is fluid to new datasets. It will simply start
traversing new layers when these are added. The algorithm will find fraud
patterns with a probability proportional to the out-degree per hop. This is
reasonable as we can assume that entities connected in a long chain have less
in common. If that is not the case, we can simply add in new links to
strengthen a connection.